High-res images
The Library is committed to providing the best possible access to our digitised images so we have decided to replace as many of the images in our Flickr Commons account with high-resolution files that we can.
The Library is currently putting new systems in place to manage all of our collection catalogues including a method for downloading high-resolution files but this will take a bit longer as we work through the user-experience requirements.
The Library joined Flickr Commons in 2008 and currently have almost 3000 images in the account with a variety of different file sizes for users to download.
Using the Flickr API the DX Lab has been able to replace most of the images now with high-resolution files. This process was a little more complicated than we initially thought and required a complex set of procedures for us to complete. Here is what we had to undertake. (Please note in some cases the high-resolution file was not available for replacement)
Technical stuff: by Luke Dearnley (Lab developer)
When Paula first asked me to write some code to replace all the Library’s images in the Flickr Commons with hi-res versions I thought it would be a snap, especially since I had written many scripts that interacted with the Flickr API in the past. However, it turned out to be a much more challenging job than I anticipated.
Looping through the existing images was easy enough, and the Replace API method is well documented, but how to match the image in Flickr with the corresponding hi-res version on the Library’s servers? Flickr, in all their wisdom, doesn’t store the original filename of the uploaded file anywhere, so using that was not an option. The titles of the Flickr entries varied from being something which looked like a useful ID to a wild range of other things. No ‘machine tags’ had been submitted at the time of upload with a link back to the original source. But, most of the descriptions did contain a URL that seemed to point to somewhere in the collection part of the website. That seemed promising.
It turned out, however, that quite a few of the URLs pointed to the album the image came from rather than the image itself. There were around 3000 images to be dealt with so I needed an automated way of determining which of the URLs pointed to the image rather than the album. Another developer here, Ken, suggested I use an image comparison script and pointed out this one which gives you a score out of 63 for how ‘different’ the images are. Zero means they should be identical, single digit scores means they are close and if it is anything higher you are probably looking at two completely different images.
I got all the Flickr IDs and the Library URLs into a database and built a little tool that scraped the image from the Library’s URL and compared it to the Flickr image. Here are some screen shots:

The left column is the images from Flickr next to which is the image scraped from the Library’s page. In parentheses next to that is the difference score. A threshold of around 13 seemed to work best and, as you can see from the above, the algorithm got it right in all four of those cases, with the first two pairs of images being correctly identified as the same, and the second two as being different (meaning the URL points to an album).
On the whole, the algorithm got things correct but a few things tripped it up for example, images being too dark, as seen here:

Or the image being tinted differently such as in this example:

Presumably, the tinting was done by the staff member uploading it to Flickr in an attempt to correct the colours, but that change to the image was enough to confuse the image comparison algorithm. In the same vein, there were other manipulations of the images such as cropping off border areas, zooming in on parts of images and in some cases flipping the image. All of these quite understandably confused the algorithm as shown in these next few screenshots:




So after this first pass through all 2,915 images, we managed to match up about 56% of them with their relevant ‘Digital ID’, which is determined by the image’s filename. The next phase was to build a tool which attempted to find matches for the remainder.
I called this the Album Resolver. It scraped all the images of an album and compared them, in turn, against the Flickr image in question. Here is a screenshot of it in action:

To the right of the ‘best guess’ image, you can see the image difference scores for each of the album images. The lowest is then chosen as the best guess. The reason there are three images on the left is because there were three different images on Flickr that all pointed to the same album.
This was much more reliable at guessing the correct image from the album. Odd things still occurred, however, in this shot we see the album doesn’t even contain the image we are looking for:
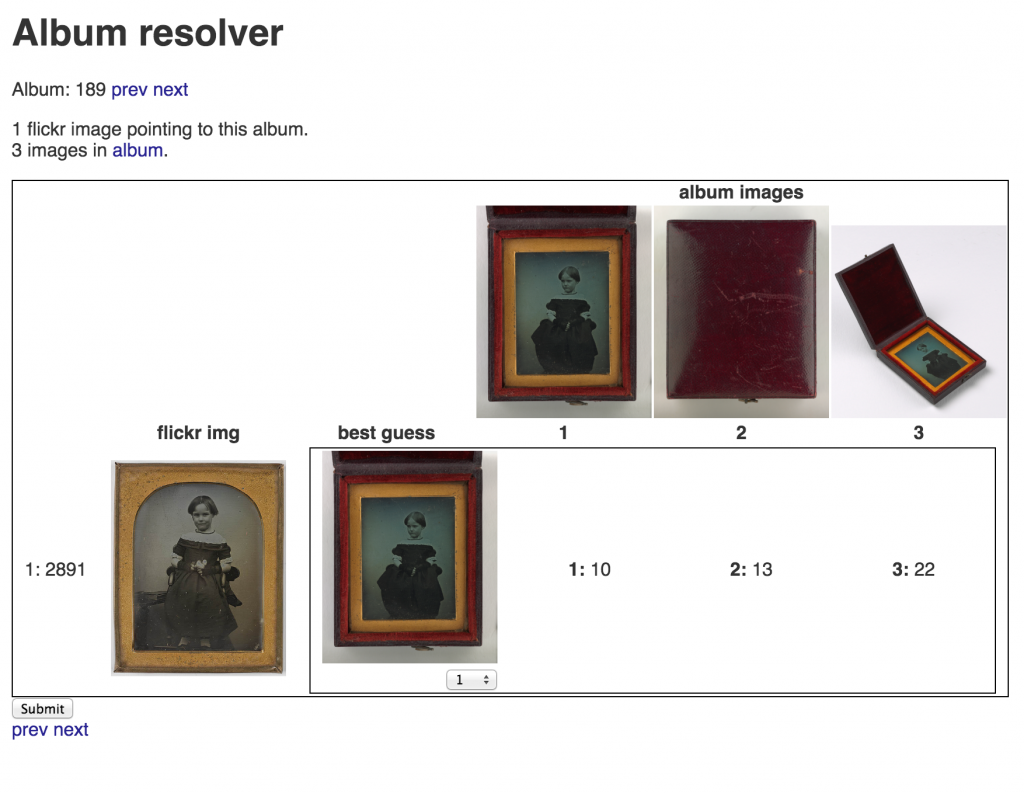
It was even good at guessing the correct image when the choices were very similar looking:

And in some cases the albums were very large, meaning the number of comparisons being done slowed the resolver down considerably. This lead me to re-write the comparison algorithm to be more efficient (it only needed to process the Flickr image once, not for every album image comparison):

The code at the core of this album resolver may be spun off at some point for use internally as a stand-alone, or browser extension Album Resolver.
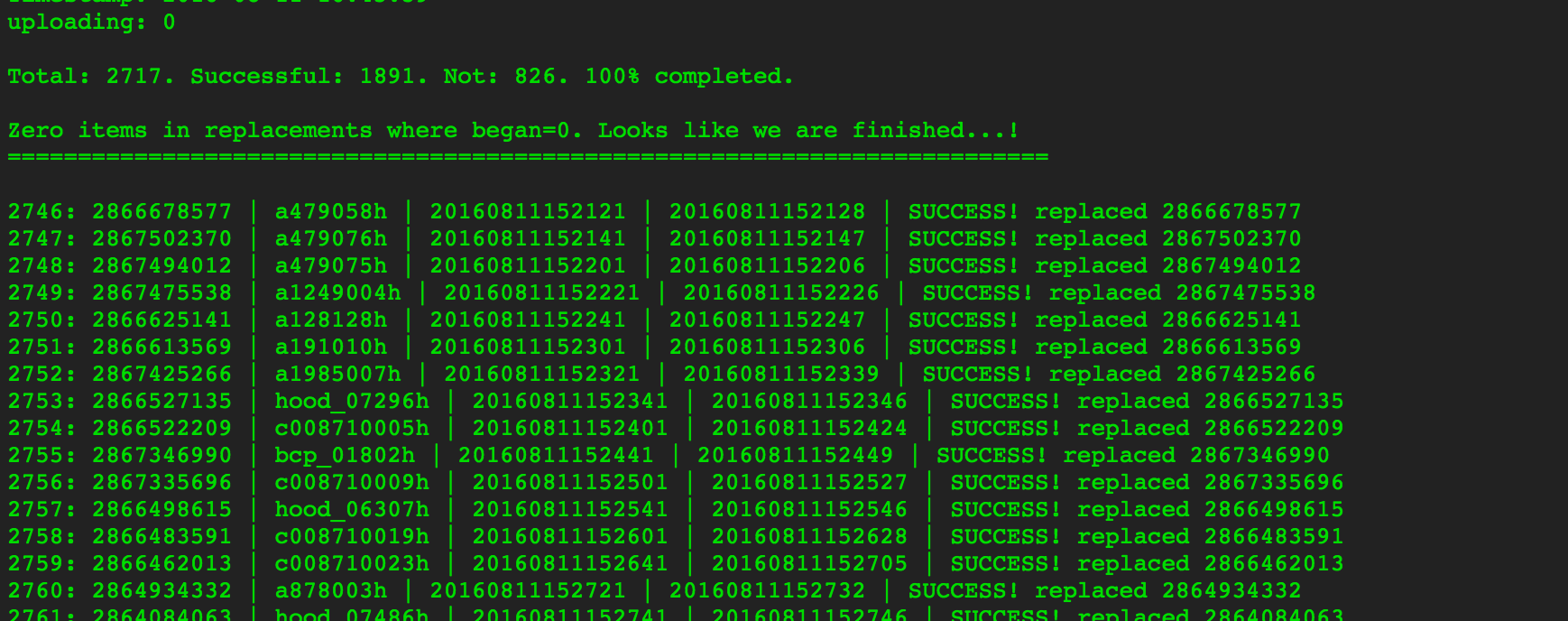
After the album resolver pass, we had managed to match 2,717 images (93.2%) to the necessary Digital ID. This ID would then be used to find the highest resolution replacement image.
Given that many of high res images are TIFs that weigh in at over 100MB it was desirable to only shift the images once (from SLNSW servers to Flickr) and avoid, say, moving them from SLNSW to a server on AWS and then to Flickr. A server was spun up internally at a network location that meant it could have the internal digital image store attached at a mount point. This was proxied through to be able to access the outside world and talking with the Flickr API was tested. Many thanks to the IT staff for this.
The next puzzle to solve was how to find a high-res image within that mount point given the Digital ID. The images are stored in a complex nested folder structure but at least their Digital ID forms part of the filename. The Linux find command was woefully slow (over 30 mins per search) and it ended up being much better to dump the entire directory listing (with full paths) into a huge text file and grep that for the sought Digital ID. This returned results in under a second.
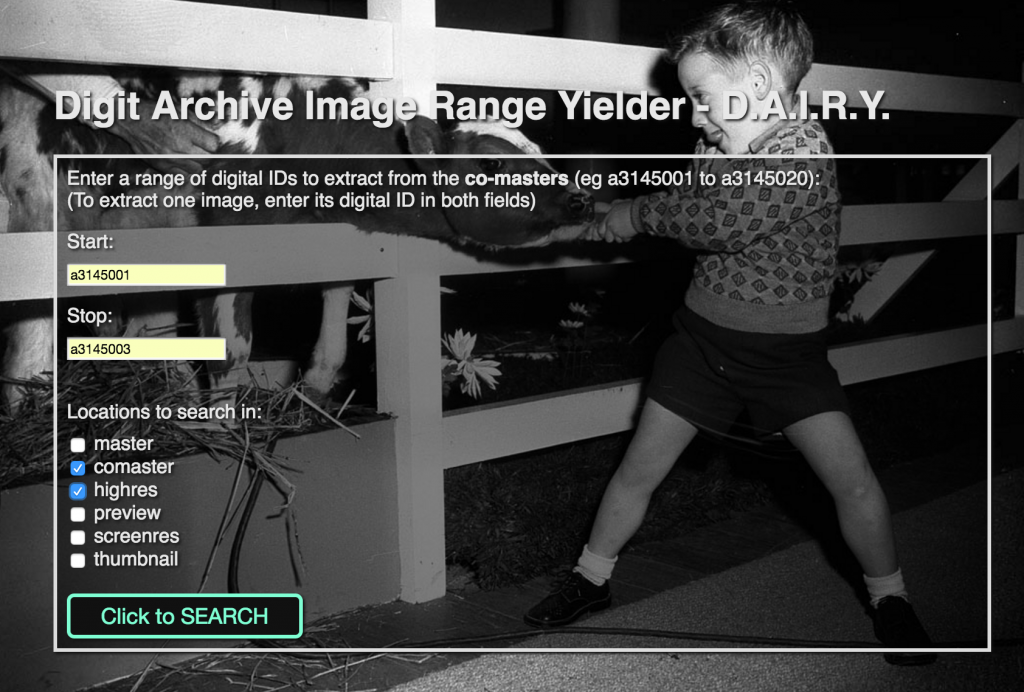
It was around this time that I overheard Paula talking about the need to download a range of high-resolution files from the Library’s digital archive to give to another staff member working on an animation project. Each of the 127 images she needed would have to be individually downloaded. I realised that the code I was writing could help solve this.
Quickly wrapping a basic web form around the grep code lead to the Digit Archive Image Range Yielder or DAIRY. This internal tool has been enthusiastically adopted by numerous staff, presumably because of its speed at finding images from a range of Digital IDs, and the time saved in downloading them as one ZIP file.
So now all the parts were in place for the big replace to begin. A bit of testing with a small set of images quickly revealed however that the dimensions of the ‘co-master’ version of the image were sometimes actually smaller than the version in Flickr, though usually by only 100-200 pixels, so these would have to be skipped. (Exactly where the larger versions that were in Flickr came from remains a mystery).
As this process would take several days to complete I set a cron job to launch the script every minute. Firstly, it checked to see that an image wasn’t already being uploaded, then found the next one to be dealt with in the database set the uploading flag to TRUE, and began the upload. The script dumped its progress into a log file and there was also a web-based tool for observing where things were up to.
It went smoothly most of the time. At one point I noticed that the Flickr API Replace method was, somewhat surprisingly, wiping out the manually entered ‘date taken’ with information from the EXIF data of the new file. Being old photos that had been digitised in the last 8 years, the EXIF data contained the date that the digitisation had occurred, meaning several hundred of the Flickr images now had taken dates that were completely wrong. Whoops. I halted the process and swiftly added two more API calls, one before the replace which obtained the date taken data, and one after that restored the correct date taken.
Another unexpected hitch was images over 200MB seemed to stop the Flickr API or maybe it was a connection time-out at our end. This stopped the process in its tracks until I coded around it.
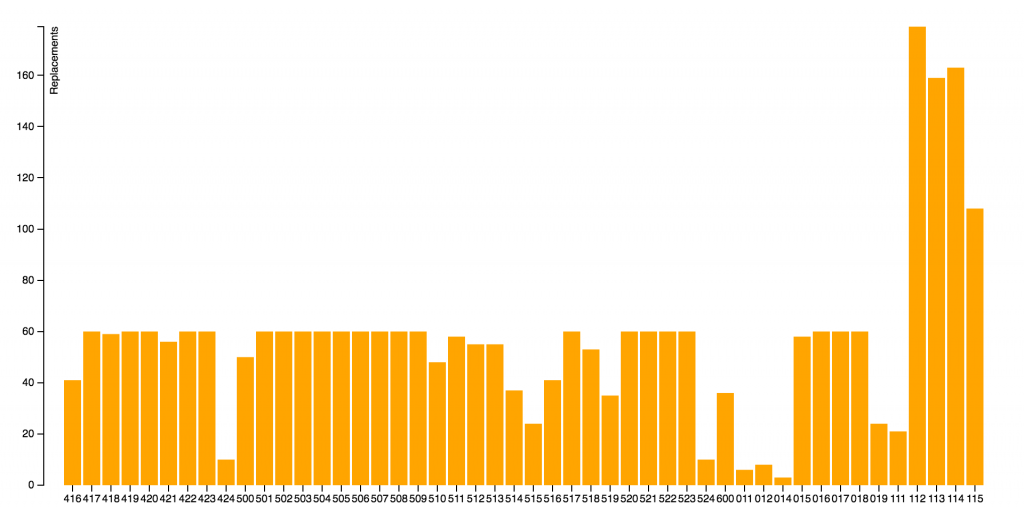
Towards the end of the process, I realised that firing off the script once a minute was probably a bit conservative and I ramped it up to every 20 seconds. Here is a graph of the number of items dealt with per hour:
Finally, we were finished. From starting with 2,915 images, we were able to match 2,717 with their correct Digital ID, 826 turned out not to have a larger version available, leaving 1,891 images successfully replaced with a higher resolution version. In many cases the improvement was dramatic:

The last step is to piece together a report from the logs and database tables for the stakeholders which details exactly what happened, allowing them to manually deal with the small number of images this automatic process couldn’t take care of.
We hope you enjoy the high-resolution files and if you use them then please let us know. You can use the hashtag #madewithslnsw.
Comments
This is great. Thanks for posting. And thanks for your continued focus on Flickr Commons!
Neil Saunders
http://www.pastpin.com
Thanks for this article – Would be good to talk to the person who wrote this as I also administer over 2000 images on Flickr for the Kununurra Historical Society and our Kununurra Museum since 2011 – Wonder if any of the API software you create is available for use by similar minded organisation – not an API programmer maybe I should be, seeing what you can do.
Kind regards,
Andrew Barker
President – http://www.kununurra.org.au
Thanks for the comment Andrew, we will be in touch via email.